CAISI’s evaluation ranked DeepSeek V4 Pro eight months behind the U.S. frontier, using an IRT-based scoring system across nine benchmarks including two private, unverifiable datasets.
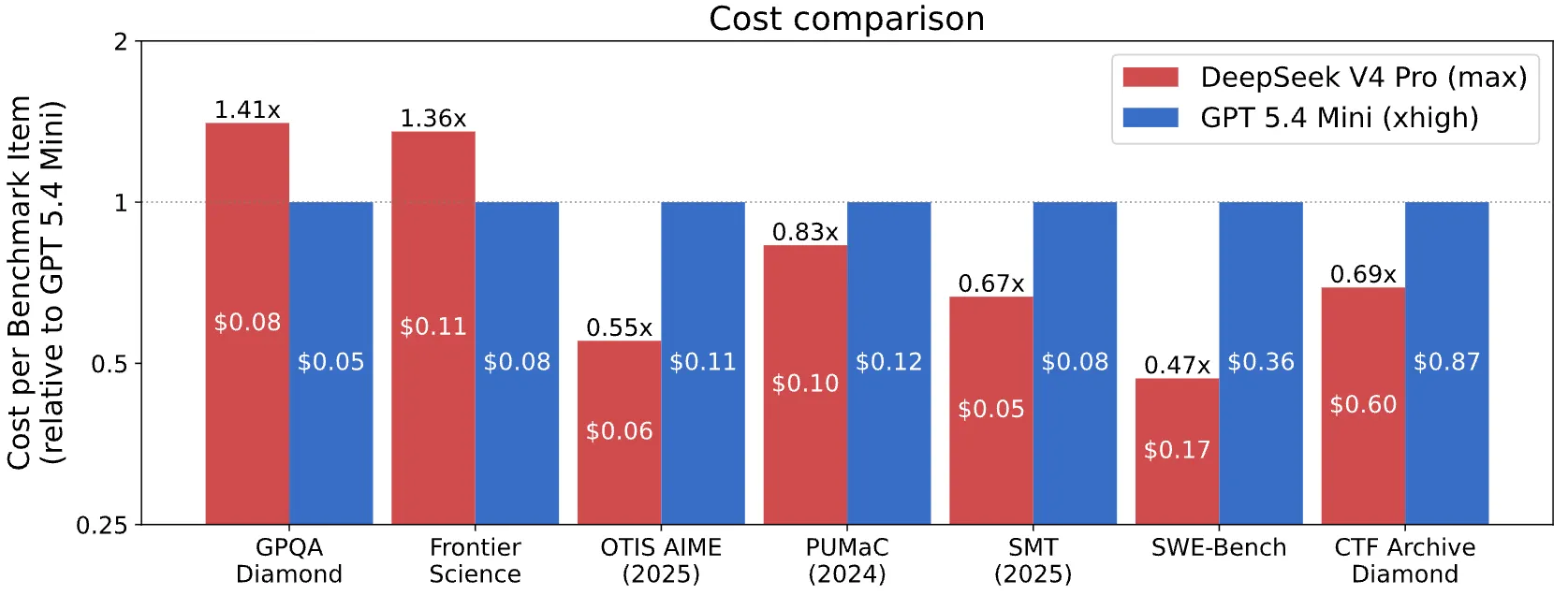
The cost comparison excluded all U.S. models deemed too expensive or too weak—leaving only GPT-5.4 mini, against which DeepSeek was still cheaper on five out of seven benchmarks.
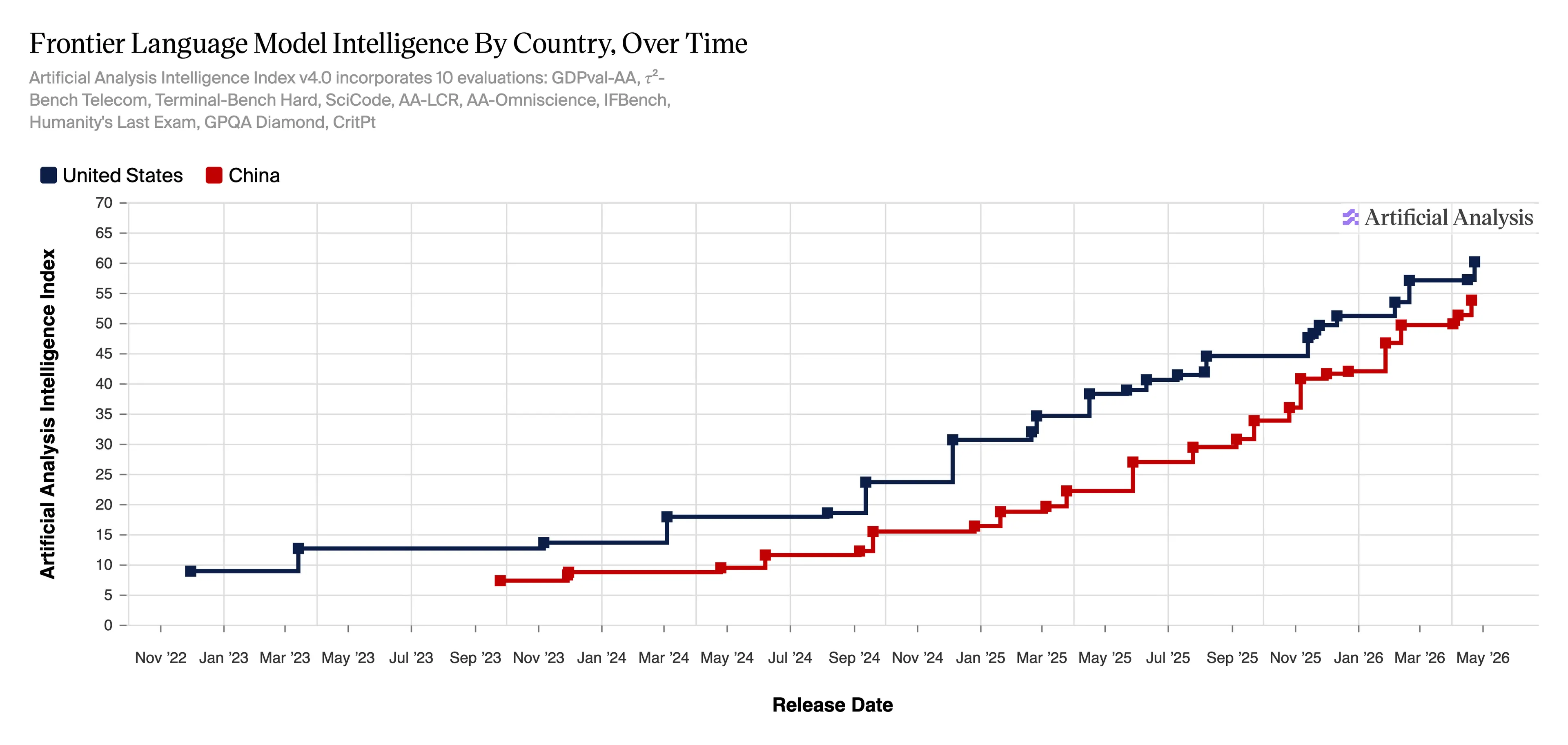
Stanford’s 2026 AI Index found the U.S.-China performance gap on public leaderboards had collapsed to 2.7%.
A U.S. government institute published its verdict on China’s most powerful AI: eight months behind, and the more time passes, the wider the gap gets. The internet read the methodology and started asking questions.
CAISI—the Center for AI Standards and Innovation, a unit inside NIST—released its evaluation of DeepSeek V4 Pro on May 1. The conclusion: DeepSeek’s open-weight flagship “lags behind the frontier by about 8 months.”
CAISI also calls it the most capable Chinese AI model it has evaluated to date.
The scoring system
CAISI doesn’t average benchmark scores like most evaluators do. Instead, it applies Item Response Theory—a statistical method from standardized testing—to estimate each model’s latent capability by tracking which problems it solves and which it doesn’t, across nine benchmarks in five domains: cybersecurity, software engineering, natural sciences, abstract reasoning, and math.
The IRT-estimated Elo scores: GPT-5.5 at 1,260 points, Anthropic’s Claude Opus 4.6 at 999. DeepSeek V4 Pro scores around 800 (±28), which is very close to GPT-5.4 mini at 749. In CAISI’s system, DeepSeek sits closer to the old generation of GPT mini than to Opus.
The points system in benchmarks score models the way standardized tests score students—not by raw percentage correct, but by weighting which problems they solve and which they miss, producing a points estimate that only means something relative to other models in the same evaluation. The more points, the better the model is in general terms, with the best model’s score becoming the reference point to see how capable a model is.
It’s impossible to reproduce CAISI’s results because two of the nine benchmarks are non-public, and in those two benchmarks is where the gap is widest. For example, GPT-5.5 scored 71% on CTF-Archive-Diamond, one of CAISI’s cybersecurity tests with DeepSeek registering around 32%.
On public benchmarks, the picture shifts. GPQA-Diamond—PhD-level science reasoning, scored as percentage correct—placed DeepSeek at 90%, one point behind Opus 4.6’s 91%. Math olympiad benchmarks (OTIS-AIME-2025, PUMaC 2024, SMT 2025) put DeepSeek at 97%, 96%, and 96%. On SWE-Bench Verified—real GitHub bug fixes, scored as percentage resolved—DeepSeek scored 74% to GPT-5.5’s 81%. DeepSeek’s own technical report claims V4 Pro matches Opus 4.6 and GPT-5.4.
For cost comparison, CAISI filtered out any U.S, model that performed significantly worse or cost significantly more per token than DeepSeek. Only one model cleared the bar: GPT-5.4 mini. That’s the entire U.S. frontier, filtered to a single entry.
DeepSeek came out cheaper on 5 of 7 benchmarks even beating OpenAI’s tiniest and least capable AI model.
The counterargument: Is the gap bigger or smaller?
Criticizing CAISI’s methodology doesn’t fully vindicate DeepSeek. The AI developer under the pseudonym Ex0bit pushed back directly: “There’s no ‘gap’, and no one’s 8 months behind. We’ve been trolled on every closed U.S drop and flexed on with open weights.”
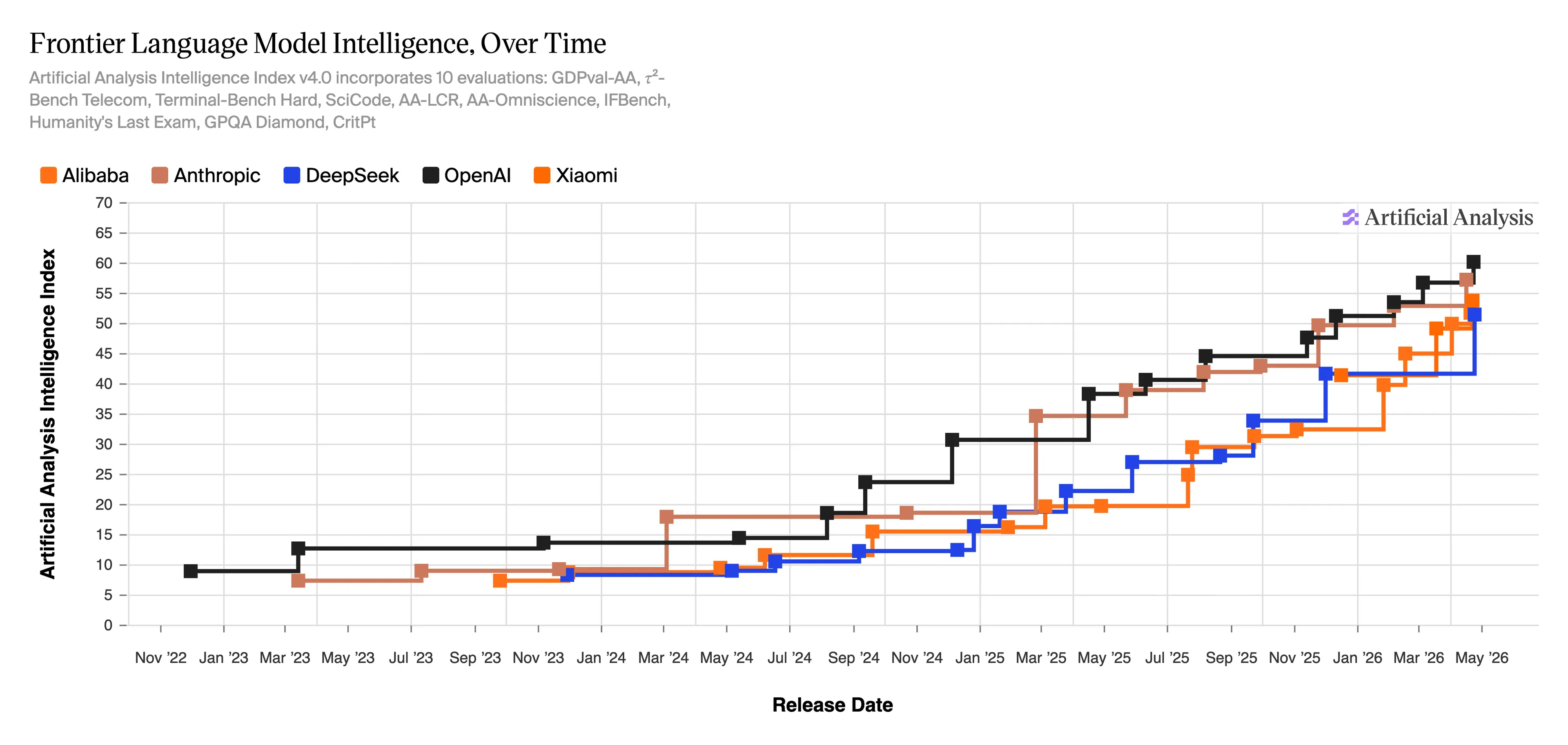
The Artificial Analysis Intelligence Index v4.0—a rating system tracking frontier model intelligence across 10 evaluations—shows OpenAI near 60 points and DeepSeek in the low 50s as of May 2026, compressed far tighter than a year ago.
Based on standardized benchmarks, their methodology shows the gap is actually getting smaller.
When DeepSeek first emerged in January 2025, the question was whether China had already caught up. U.S. labs scrambled to respond. Stanford’s 2026 AI Index—released April 13—reports the Arena leaderboard gap between Claude Opus 4.6 and China’s Dola-Seed-2.0 Preview is shrinking, separated now by only 2.7%.
CAISI plans to release a fuller IRT methodology write up in the near future.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.
The FSNN News Room is the voice of our in-house journalists, editors, and researchers. We deliver timely, unbiased reporting at the crossroads of finance, cryptocurrency, and global politics, providing clear, fact-driven analysis free from agendas.
We and our selected partners wish to use cookies to collect information about you for functional purposes and statistical marketing. You may not give us your consent for certain purposes by selecting an option and you can withdraw your consent at any time via the cookie icon.
Cookies are small text that can be used by websites to make the user experience more efficient. The law states that we may store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses various types of cookies. Some cookies are placed by third party services that appear on our pages.
Your permission applies to the following domains:
https://fsnn.net
Necessary
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Statistic
Statistic cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
Preferences
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
Marketing
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.