Researchers from Huawei and three partner institutions released Claw-Anything, a benchmark that evaluates AI agents on personal-assistant tasks.
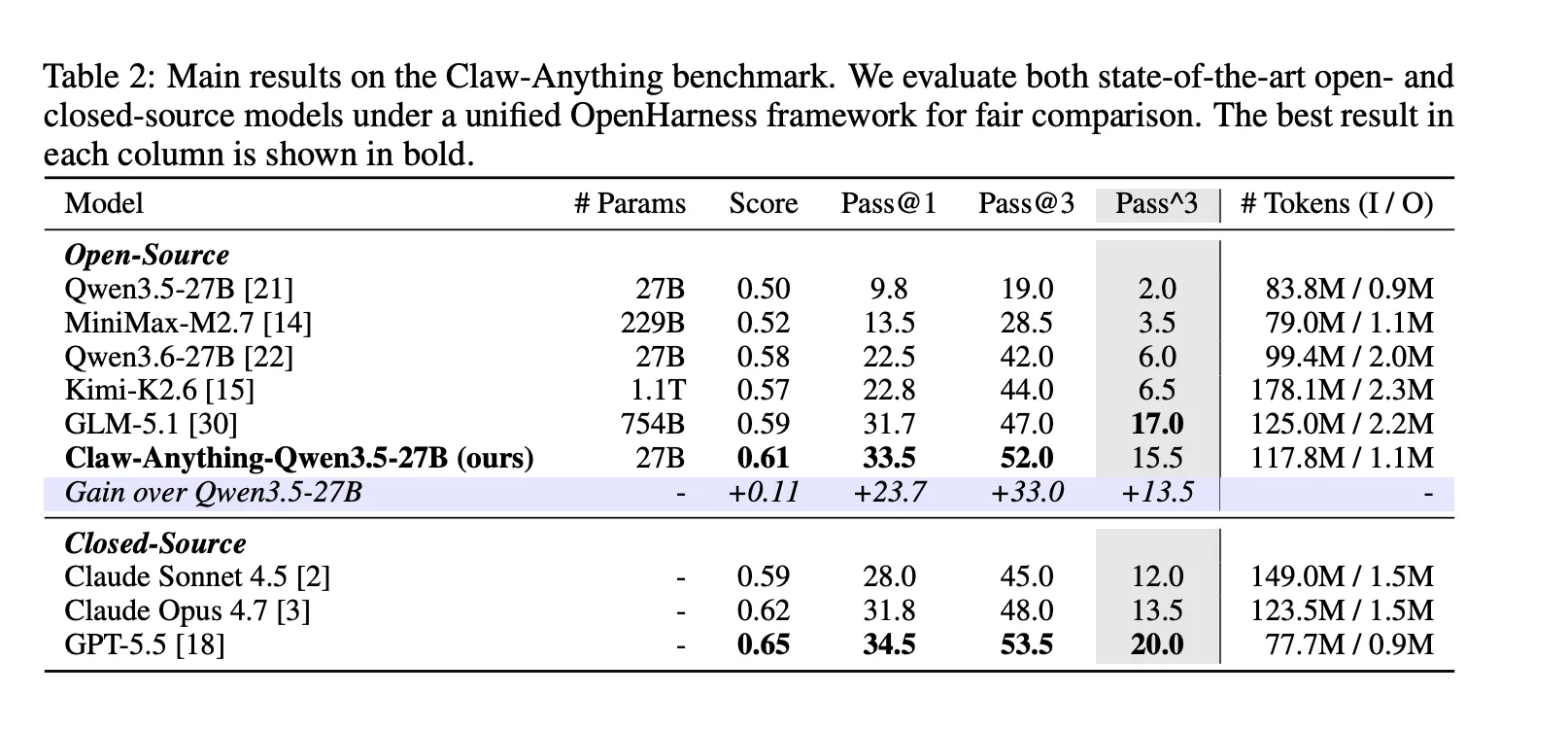
GPT-5.5, OpenAI’s flagship model, scored only 34.5% on the pass@1 metric—far below its scores on existing benchmarks, suggesting current tests are measuring the wrong things.
The team also released an automated data pipeline that produced 2,000 training environments; fine-tuning an open-weight model on that data improved task success by 23.7%.
The pitch for AI personal assistants has always been the same: Give the agent access to your digital life and it handles the rest. Your emails, your calendar, your notes, your devices—all of it. Your AI knows. Your AI acts. You sleep.
Researchers from Huawei Technologies, Beijing Institute of Technology, Peking University, and the Chinese Academy of Sciences just built a benchmark to see if that’s actually true. Spoiler: It’s not.
Claw-Anything evaluates AI agents across three dimensions at once: long-horizon event streams covering more than three months of simulated user activity, interdependent backend services averaging 10.1 per task, and multi-device interaction across both CLI Linux environments and GUI Android environments.
The average context window per task is 191,700 words. Most existing benchmarks sit somewhere between 1,700 and 12,000. That’s not a small gap but an entirely different problem. It’s also what real life feels like, as opposed to standardized ultra specific benchmarks.
Your AI has no idea what’s going on
The benchmark is scored on pass@1—the probability the agent completes a task correctly on its first try, no do-overs. A task might ask the agent to cross-reference a price alert on a product it found weeks ago, check the user’s calendar for a relevant appointment, and act on both from a phone. Another might ask it to pull recent work from notes, email threads, and Slack, then produce a presentation from scratch.
These are things people actually ask assistants to do. Turns out AI isn’t very good at them. GPT-5.5, per Decrypt’s previous coverage, is OpenAI’s best model, built with agentic, long-horizon tasks in mind. It scored 34.5%.
“Current models remain unreliable even when given broader access to the user’s digital world,” the Claw-Anything paper reads. Several models that look impressive on other benchmarks dropped further.
The benchmark also grades proactive assistance separately, meaning cases where the agent spots a need and acts without being asked. Most benchmarks don’t test this. Claw-Anything does, and the gap is stark: Agents scored 25.9% on reactive tasks and just 6.7% on proactive ones.
Why most benchmarks don’t tell you this
The researchers make a pointed argument: Existing benchmarks treat AI agents like task solvers given a clean desk. Claw-Anything treats them like personal assistants dropped into an actual messy life—irrelevant events, conflicting signals, months of accumulated noise. The agent has to figure out what’s relevant before it can do anything useful.
The ablation results make the multi-service dependency especially clear. When tools required for cross-service tasks were removed, success rates fell to nearly zero, because most tasks require agents to retrieve information and act across multiple backends rather than within a single one.
This is not a new genre of problem in AI evaluation. OpenAI declared SWE-bench contaminated earlier this year after scores collapsed from roughly 70% to 23% on a less leakage-prone version. That was about data hygiene. This is about something more fundamental—whether the benchmarks are even asking the right question.
On the constructive side, the team released the pipeline that generated the benchmark alongside 2,000 training environments. Fine-tuning Qwen3.5-27B on 1,500 successful agent trajectories improved pass@1 by 23.7%—enough to beat several closed-source models on the leaderboard, including Claude Sonnet.
The researchers identify cross-service coordination as the benchmark’s primary remaining challenge for the field. The dataset is on Hugging Face and the code is on GitHub.
Daily Debrief Newsletter
Start every day with the top news stories right now, plus original features, a podcast, videos and more.
The FSNN News Room is the voice of our in-house journalists, editors, and researchers. We deliver timely, unbiased reporting at the crossroads of finance, cryptocurrency, and global politics, providing clear, fact-driven analysis free from agendas.
We and our selected partners wish to use cookies to collect information about you for functional purposes and statistical marketing. You may not give us your consent for certain purposes by selecting an option and you can withdraw your consent at any time via the cookie icon.
Cookies are small text that can be used by websites to make the user experience more efficient. The law states that we may store cookies on your device if they are strictly necessary for the operation of this site. For all other types of cookies, we need your permission. This site uses various types of cookies. Some cookies are placed by third party services that appear on our pages.
Your permission applies to the following domains:
https://fsnn.net
Necessary
Necessary cookies help make a website usable by enabling basic functions like page navigation and access to secure areas of the website. The website cannot function properly without these cookies.
Statistic
Statistic cookies help website owners to understand how visitors interact with websites by collecting and reporting information anonymously.
Preferences
Preference cookies enable a website to remember information that changes the way the website behaves or looks, like your preferred language or the region that you are in.
Marketing
Marketing cookies are used to track visitors across websites. The intention is to display ads that are relevant and engaging for the individual user and thereby more valuable for publishers and third party advertisers.